Graph Layout, Models vs. Views, and Computational Thinking
Money for me to keep working full-time on Software Carpentry hasn't materialized, so as I've mentioned in a couple of recent posts, I'm trying to find a way to organize the course material more coherently in the hope that other people will (finally) start to contribute content as well. As part of that, I have spent the last two days trying to draw a graph showing the questions Software Carpentry seeks to answer, and the concepts that underpin the answers. It's been harder than I expected, and I think the reasons might give some insight into how a computational thinker thinks.
Option #1: use a generic drawing tool like Microsoft Paint. The upside is, it's easy. The downside is, it stops being easy as soon as I want to change things or collaborate with other people. Paint doesn't have any notions of boxes, circles, or text: instead, it manipulates the pixels in images directly. If I create a box with a text label, I can't group them together to make a single object, because there are no objects. I could select and cut a region containing the box and label, then paste it elsewhere, but that wouldn't move the links connecting the box to other boxes.
Storing my graph as an image also makes it hard to collaborate. I can put the image in a version control repository, but if Grace edits her working copy while I'm editing mine, how do we merge our changes? It seems strange to me that image diff-and-merge tools don't exist for Subversion, Mercurial, and other systems, but that's a yak I'm not going to shave today.
Option #2: use an object-based drawing tool like Visio (or a reasonably modern PowerPoint). This lets me group things, and links will stay attached as I move things around, but I still can't collaborate. Switching to OpenOffice or Inkscape doesn't help: yes, they can save things as XML instead of in a binary format, but existing diff and merge tools work don't understand the structure of that XML, never mind its semantics, so they report differences at the wrong level. It's as if my diff tool was working at the bitwise level, and reporting this:
01101101 01100001 01110100 01101101 01100001 01101110
instead of:
m a t m a n
The same is true of interactive graph editors like yEd, Gephi, and so on. If I have to eyeball two versions of a file and copy differences by hand, collaborating is going to be slow and error prone.
Option #3: store my graph in a textual form that can be diffed and merged, and convert that textual form into the graphical representation I want (where "graphical" in this case means "visual", not "nodes and edges"). This is what LaTeX and HTML do: the human being creates content, and a tool transforms that content into something more readable. Most of the translation is automatic, but all tools of this kind provide some way to control things more exactly, e.g., to force hyphenation at a particular point in a word, to center-align a title, and so on.
The best-known tool of this kind for graphs is probably GraphViz. Here's a snippet of the GraphViz .dot file I've written over the last couple of days:
strict graph Course {
q_automation [label="How can I automate this task?"];
q_avoid_bugs [label="How can avoid creating bugs in my programs?"];
q_code_reuse [label="How can I make my code easier to reuse?"];
…more of these…
a_algorithm_data_structure [label="Use the right algorithms and data structures"];
a_binary_data [label="Manipulate data at the bit level"];
a_build_tool [label="Use a build tool"];
…more of these…
q_automation -- a_build_tool;
q_speedup -- a_parallelize;
q_team_programming -- a_code_review;
…more of these…
}
So far so good: nodes and edges occupy a single line each, so differences will be easy to see. And if I'm brave, and speak a little C, I can put C preprocessor commands in my file to make it look like this:
/*
#define ANSWER(name, str) name [shape=box,fontcolor=red4,color=red4,margin="0.05,0.0",label=str]
#define QUESTION(name, str) name [shape=octagon,fontcolor=navyblue,color=navyblue,margin="0.05,0.0",label=str]
#define QA(q, a) q -- a [arrowhead=open]
strict graph Course {
QUESTION(q_automation, "How can I automate this task?");
QUESTION(q_avoid_bugs, "How can avoid creating bugs in my programs?");
QUESTION(q_code_reuse, "How can I make my code easier to reuse?");
…more of these..
ANSWER(a_algorithm_data_structure, "Use the right algorithms and data structures");
ANSWER(a_binary_data, "Manipulate data at the bit level");
ANSWER(a_build_tool, "Use a build tool");
…more of these…
QA(q_automation, a_build_tool);
QA(q_speedup, a_parallelize);
QA(q_team_programming, a_code_review);
…more of these…
}
Why would I do this? Well, I'm eventually going to add two more kinds of nodes: concepts (like "metadata") and specific lecture topics (like "regular expressions"). I may want to show all four kinds in a single graph, but I will probably also want to show just the answers and lecture topics, or just the questions and concepts, and so on. With an interactive tool like Gephi, I'd have to hide some nodes, then rearrange the ones that were still visible (and then put them back when I un-hid the hidden nodes). If I'm compiling, on the other hand, I can undefine the macros for the nodes and links I'm not interested in on the command line when I run the C preprocessor, and then feed the output to GraphViz for layout.
The key idea here is the separation between model and view. The model is the stuff: in this case, the nodes in the graph and the edges connecting them. The view is how that model is presented to a human being, such as a static image (almost impossible to edit meaningfully, but easy to understand), or a dynamic rendering in a tool like Gephi (easy to edit, and also easy to understand). The textual representation is actually just another view: it isn't the model any more than what's on screen in the Gephi GUI. We often think of the textual representation as being the model because it's what we store, and what other tools that are more obviously view-ish take as input.
At this point, I'd like to say "Q.E.D." and move on, but there's still one big problem: my compiler is broken. Well, it's not really mine–I didn't write the GraphViz tools–and it isn't really "broken", it just does a lousy job of laying out my particular graph. I've tried tweaking various layout parameters to no avail; what I've fallen back on in frustration is to store my nodes and edges in .dot file, then load it into Gephi, let it lay things out, then tweak the results manually. This is time consuming, but I'm willing to live with that: I know that graph layout is a wickedly hard problem, and anyway, I only expect to re-organize the graph every once in a while.
For the question-and-answer graph, the best result I've obtained so far looks like this (with labels removed for clarity):

What I'm can't live with is that this approach doesn't let me round-trip my edits. What I have in my file isn't actually a GraphViz graph; instead, it's a bunch of C preprocessor macros that compile into such a graph:
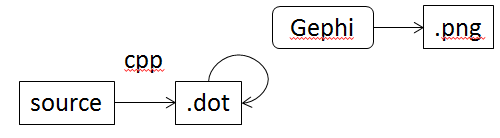
Gephi can save my changes in a .dot file, but that's not what I want to store. I want the thing I save to be written in terms of my macros. Yes, I could write a small program to read node coordinates out of the Gephi-generated .dot file and stuff them back into my source file, or build an output adapter for Gephi, but that would be yak shaving: my goal here is to redesign a course, not to write Java to store a graph in format no more than three people will ever use.
I don't have a tidy solution yet, and probably never will–as Tom West said, "Not everything worth doing is worth doing well." But as I said at the outset, I hope this story gives a bit of insight into how I think when I'm thinking computationally, and helps you figure out how to manage your data when the time comes.